


Introduction:
Data Science Interview Questions and Answers:- Everything is easy and available in a microsecond in today’s world. On the other hand, the flip side of the coin is quite opposite. To make things simpler and easier for us, they have a data analyst that works 24 hours a day, 7 days a week to provide a rapid answer to the most difficult problem. Peter Naur, an expert in the field of computer science, coined the phrase in 1960. In his 1974 book, Concise Survey of Computer Methods, he outlined the basic components of the methods and practices utilized in data science. DJ Patil and Jeff Hammerbacher were two names that made news in 2008. These are likely names you’re familiar with if you’re a data scientist. They are known for promoting the phrase “data science,” but they also represent the contemporary data scientist—that is, someone who uses content skills in any environment that requires it, such as healthcare, e-commerce, social networks, and media, to mention a few.

In basic terms, data science is an interdisciplinary branch of study that makes use of data for different investigation and analytical objectives in order to draw discoveries and purpose from it. Statistics, improved strategy, information science, and other abilities are all required in data science. Data science may be used to learn about people’s behaviours and processes, to create algorithms that handle vast quantities of data rapidly and effectively, to improve the security and privacy of sensitive data, and to lead data-driven decision-making.
Data science may discover similarities in apparently unorganized or unrelated data, allowing conclusions and forecasts to be made. Tech firms that acquire customer data can utilize ways to transform that data into valuable or profitable information sources. Hence, in short, the primary goal of data science is to concentrate on the big picture while giving comprehensive and exact results to the general population. More broadly, a data scientist is someone who understands how to extract meaning from and analyses data, which necessitates both statistical and machine learning tools and methodologies, as well as being human. Because data is never completely clean, she spends a lot of effort gathering, cleaning, and munging it.
Scope of Data Science:
A data scientist is someone who has worked in a variety of disciplines. The data scientist can create the issue summary and project goals following the company’s objectives. They use machine learning and artificial intelligence to discover patterns and trends and create data-driven forecasts. Data scientists are in high demand in India, as seen by the rising need for the scope of data science.
Certainly, there is a large scope of data science. Data is quickly becoming the most valuable asset on the planet. Data is being referred to as the future fuel, while analytics is being referred to as the machine, according to scientists. The scope of data science in India is quite promising. Organizations all around the globe are working on techniques to structure and utilize data in order to achieve their strategic priorities. Data Science combines Computer Science, Applied Mathematics, Statistical, and Marketing in a unique way.
Kindly go through the top 50 Data Science Interview Questions Answers for 2021 for your reference.
Q.1 What is Data Science, exactly? Make a comparison between supervised and unsupervised learning.
Answer: Data Science is a collection set of tools, methods, and advanced analytics techniques that attempt to uncover underlying knowledge in large amounts of data.
The following are the distinctions between supervised and unsupervised learning:
Supervised Learning
Unsupervised Learning
| The data in the input is annotated. | The data in the input is unmarked. |
| It makes use of a training data set. | It input a dataset is used. |
| t’s used to generate forecasts. | To analyze. |
| Allows categorization and correlation to be performed. | Identification, Density Estimation, and Dimension Reduction are all possible. |
Q.2 How would you describe Markov chains?
Answer: A random variable is a Markov chain.
The predicted chance of each state in a Markov chain is solely determined by the present state. The diagram above depicts a Markov chain model in which each step has an output that is solely dependent on the current state. Keyword suggestion is a great example.
When we type a sentence, the model suggests the next word, which is based only on the preceding word but nothing else. The Markov chain model was already on a similar paragraph, in which the next word after a provided word is saved for all of the words in the dataset. The following terms are recommended based on the training data output.
Q.3 What is the relevance of R in Data Visualization?
Answer: R is used in graphs and charts because it has numerous built-in functions and packages that aid in the process.
ggplot2, leaflet, lattice, and other packages are among them.
R may be used for exploratory data analysis and extraction of features.
Almost every form of the graph may be generated using R.
R makes it easier to customize visuals than Python.
Q.4 What is the ROC curve, and how does it work?
Answer: A graph with the False positive rate on the x-axis and the Positive predictive rate on the y axis is known as a ROC curve. The ratio of true positives to the total number of positive samples is known as the True positive rate. The ratio of False positives to the total number of negative samples is known as the False Positive Rate. The ROC curve is constructed by plotting the FPR and TPR on different threshold values.
The ROC curve’s area under the curve varies from 0 to 1. The ROC of a totally random model is 0.5, which is depicted as a straight line. The model is better the more the ROC curve deviates from this straight line. For the classification algorithm, ROC curves are employed.
Q.5 What does the acronym NLP stand for in Data Science?
Answer: Natural language processing (NLP) is an acronym for natural language processing.
It is the science of teaching computers how to learn vast quantities of textual material. Expression, stop words removal, splitting, sentiment analysis, and other NLP techniques are examples.
Q.6 Calculate the accuracy and recall rate using the equation.
Answer: The number of correct positive predictions made is referred to as precision.
Precision is measured by dividing the total number of true positives and false positives by the number of true positives.
Precision = (True Positives + False Positives) / (True Positives + False Positives)
Precision is calculated as the quantity of correct positive predictions produced out of all possible positive predictions.
The number of true positives divided by a total number of numbers of true positives and false negatives is used to compute recall.
True Positives / (True Positives + False Negatives) = Recall
Q.7 What is the purpose of using the summary function?
Answer: To get a summary of all the numeric values in a dataset, utilize summary functions.
The describe () method, for example, may be used to provide an overview of all the datasets passed to it.
column name. Describe () will return the following values for all of the column’s numeric data.
Count
Mean
Std-Standard deviation
Min-Minimum
25 percent
50 percent
75 percent
max-Maximum
Q. 8 What is the distinction between a failure and a residual failure?
Answer: The discrepancy between the anticipated and actual value is referred to as an error.
Mean Absolute Error (MAE), Mean Squared Error (MSE), and Root Mean Squared Error (RMSE) are the most used methods for measuring mistakes in data science (RMSE).
The discrepancy between a collection of observed values and they are arithmetical mean is known as residual. A mistake is usually undetectable, but a residual error can be shown on a graph. The difference between observed data and the actual population is represented by error. A residual, on the other hand, depicts how observational values varies from data from the sample population.
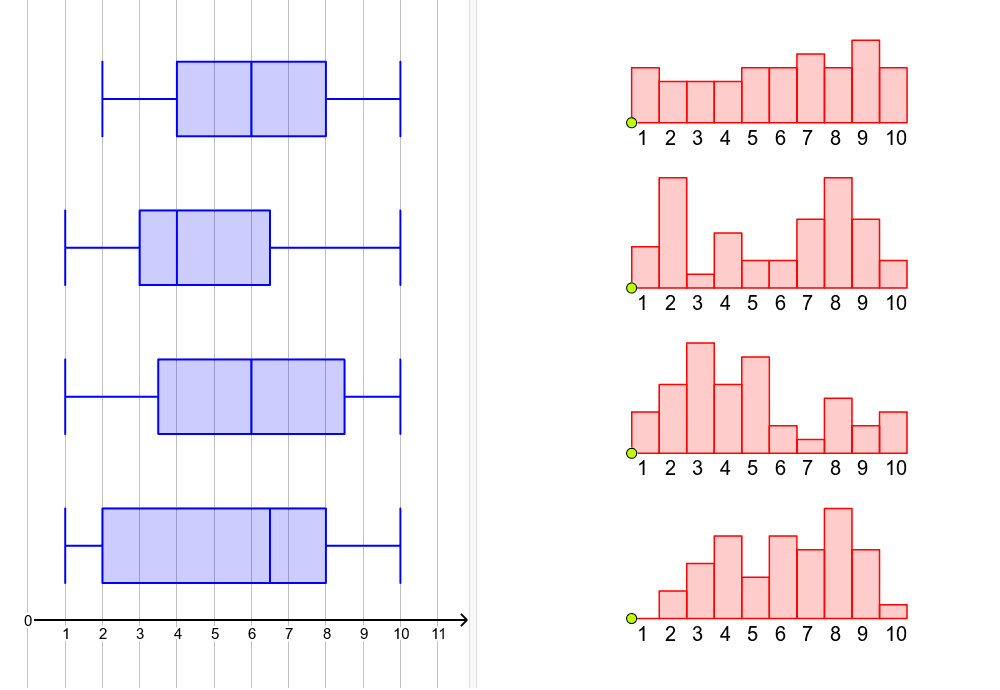
Q. 9 What is the distinction between the histogram and a box plot?
Answer: Histograms and box plots are both used to visualize the distribution of values for a certain characteristic. The histogram is used to determine the data’s underlying probability distribution. Boxplots, on the other hand, are much more commonly employed to evaluate multiple datasets. Histograms have more information and take up more space than boxplots.
Q. 10 How do you handle a binary categorization that isn’t balanced?
Answer: When doing binary classification, if the data set is unbalanced, the model’s performance cannot be accurately predicted using simply the R2 score.
For example, if one of the two classes have significantly less data than the other, the conventional correctness will only account for a tiny fraction of the smaller group.
Even if just 5% of the instances are from the smaller group, and the model correctly identifies all outputs from the larger class, the accuracy is still about 95%.
However, this is incorrect. We can cope with this by doing the following:
- Other techniques for calculating model performance, such as precision/recall, F1 score, and so on, can be used.
- Resample the data using techniques such as under sampling (decreasing the sample size of the bigger class), oversampling (raising the sample size of the smaller class using repetition, SMOTE, and other approaches), and so on.
- K-fold inter-validation was used.
- Using ensemble techniques to examine the entire sample of the smaller class and only a portion of the bigger class in each decision tree.
Q. 11 What is Selection Bias and how does it affect you?
Answer: Selection bias is a type of mistake that happens when a researcher selects the people who will be researched. It’s usually associated with studies in which the group members aren’t chosen randomly. The shortlisting effect is a term used to describe this phenomenon. It is a statistical analysis that has been distorted as a result of the sample collection technique. Some of the study’s results may be erroneous if the selection bias is not considered.
Q. 12 What are the four categories of Selection Bias?
Answer: The four categories of selection bias:
- Bias in sampling: It is a systemic mistake caused by a non-random sampling of a demographic, which causes some individuals of the population to be less likely than others to be included, resulting in a biased sample.
- Time interval: An experiment may be ended early if an extreme value is achieved (typically for ethical concerns), although the extreme value is most likely to be reached by the variable with the greatest variation, even if other variables have a comparable mean.
- Data: When particular sets of data are selected as the sample to support a hypothesis or reject poor data, rather than according to previously established or widely recognized standards.
- Attrition bias: This is a type of selection. Attrition bias (loss of participation) causes selection bias by discounting trial disciplines that did not run to completion.
Q.13 What is the bias-variance trade-off?
Answer: Bias: A bias is an inaccuracy created in your network as a result of the machine learning technique being oversimplified. It may result in misclassification. When you educate your network, it makes simpler assumptions to make the goal function clearer to comprehend.
Machine learning algorithms with minimal bias – Decision Trees, k-NN, and SVM Machine learning methods with high bias — Linear Regression, Logistic Regression
Variance: is an inaccuracy created in your network as a result of the complicated machine learning method; your model learns noise from the training set and performed badly on the test data set. It might result in overfitting and excessive hypersensitivity.
Typically, as the complexity of your network increases, you will observe a drop-in error owing to decreasing bias in the model. This is only valid until a specific point. As you continue to make your model more complicated, you wind up over-fitting it, and your model suffers from excessive variation.
Bias -Variance trade-off: To achieve good prediction performance, every supervised machine learning method should have low bias and low variance.
- The k-nearest neighbour method has a low bias and a large variance, but the trade-off may be altered by raising the value of k, which increases the number of neighbours who participate in the prediction and therefore raises the variation.
- The SVM (Support Vector Machine) has a low bias and a large variance, but the trade-off may be adjusted by raising the C parameter, which impacts the number of breaches of the boundary permitted in training data, increasing the bias while decreasing the variance. In machine learning, there is no getting around the connection between bias and variation. As the bias is increased, the variance decreases. Raising the variance reduces bias.
Q. 14 What is dimensionality reduction and what are the benefits of it?
Answer: Dimensionality reduction is the process of decreasing the number of characteristics in a dataset.
There are several ways for reducing dimensionality, including:
- Methods for Choosing Features
- Matrix Factorization is a kind of matrix factorization.
- Multiple Learning
- Methods for Using Autoencoders
- Linear Discriminant Analysis (LDA)
- The principal component analysis (PCA)
- Analyze the principal components (PCA)
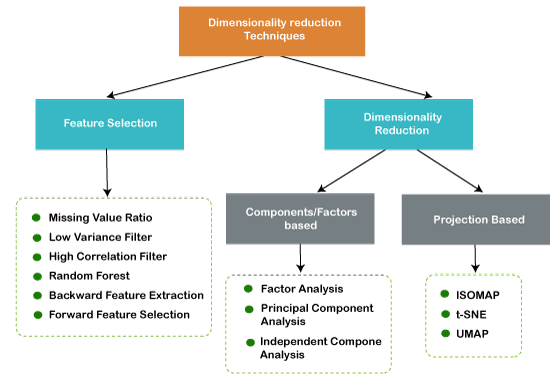
One of the major motives for dimensionality reduction is the curse of dimensionality. The model grows increasingly complicated as the number of features rises. However, if the number of data points is too little, the model will begin learning or overfitting the data. The data will not be generalized by the model. The curse of dimensionality is a term used to describe this situation.
- Dimensionality reduction also has the following advantages:
- Time and storage space are saved.
- Data visualization and visual representation in 2D or 3D become easier.
- The complexity of space is decreased.
Q.15 How should a deployed model be maintained?
Answer: It is necessary to sustain a model once it has been deployed. The data is provided may vary over time. In the instance of a model that predicts housing values, for example, housing costs may rise over time or vary owing to other factors. The model’s efficiency on fresh data can be recorded.
The following are some popular methods for ensuring accuracy:
- Negative test data should be fed into the model regularly. It’s ok if the model has a low accuracy with negative test data.
- An Auto Encoder must be created that calculates the Reconstruction error value using anomaly detection algorithms. If the Reconstruction error is large, it showed that the new data does not follow the model’s previously learnt pattern.
If the model predicts new data accurately, it indicates the new data follows the pattern or generalization learnt by the model on previous data. As a result, the model may be reprogrammed using the new information. If the model’s accuracy on fresh data isn’t up to par, it may be retrained using feature engineering on the data features alongside the old data.
If the model’s accuracy is poor, it may need to be retrained from the ground up.
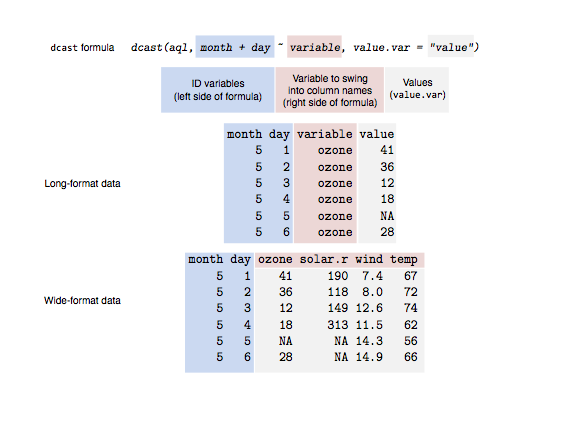
Q.16 What’s the difference between data in “long” and “wide” format?
Answer: A subject’s repeated responses will be in a single row in the wide format, for each response in its column. Each row in the long format represents a single time point for each subject. You can recognize data in a wide layout by the fact that columns usually represent groups.
Q. 17 What exactly do you mean when you say “correlation” in data science?
Answer: Correlation is regarded as the most effective method for determining and estimating the quantitative relationship between two variables. The degree of connection between two variables is measured by correlation.

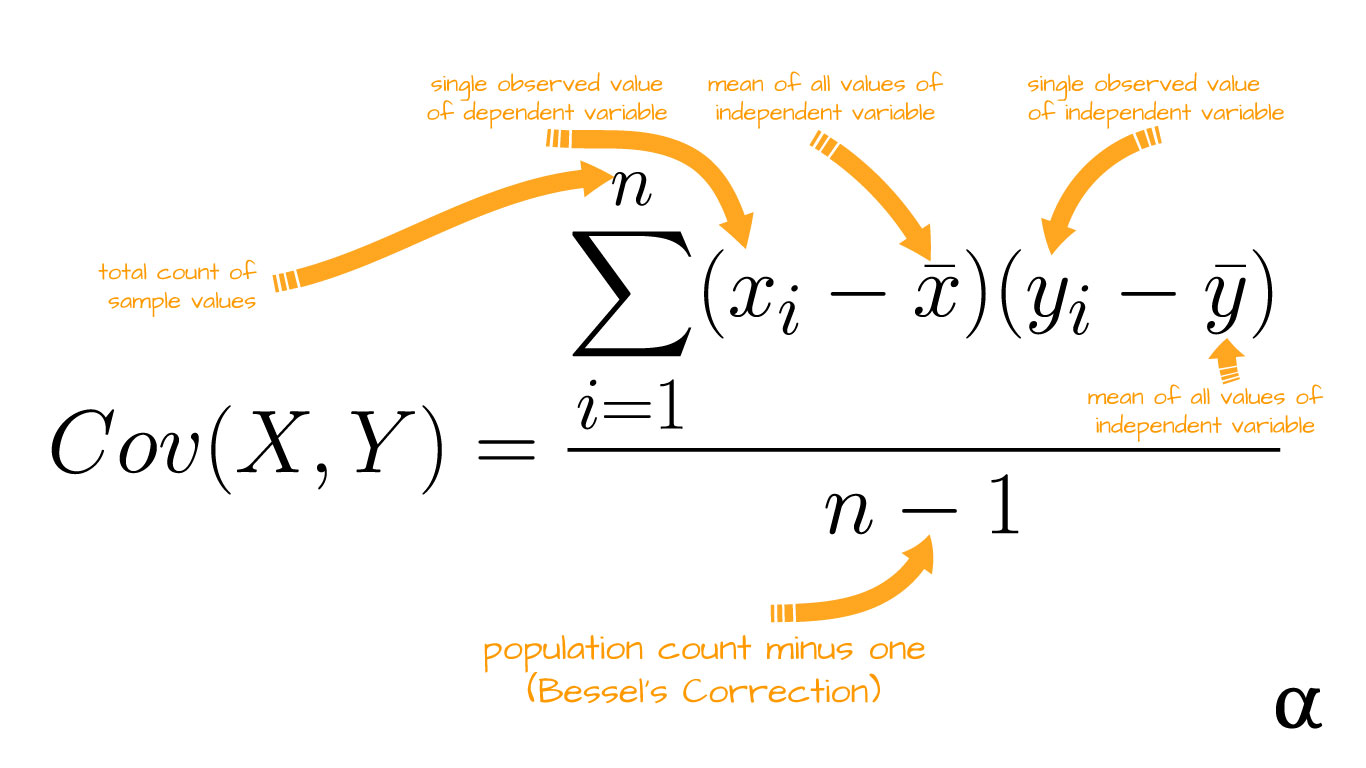
Q. 18 In statics, what do you understand by covariance?
Answer: Covariance is a metric that reflects the amount to which two random variables vary in cyclic when they fluctuate together. It’s a statistical phrase that describes the systematic relationship between two random variables in which changes in one variable are reciprocal to changes in the other.
Q. 19 What does the phrase “normal distribution” mean to you?
Answer: Data is commonly dispersed in a variety of ways, with a bias to the left or right, or it might be jumbled altogether. However, there’s a chance that data is distributed about a central value with no bias to the left or right, resulting in a bell-shaped curve with a normal distribution. A symmetric, bell-shaped curve is used to disperse the random variables.

Q. 20 In statics, what are the characteristics of the Normal Distribution?
Answer: Below is features of the normal distribution:
- One mode (unimodal)
- Symmetrical – the left and right halves are mirror reflections of one another.
- The maximal height (mode) at the mean is bell-shaped.
- The mean, mode, and median are all in the middle.
- Asymptotic
Q. 21 What is the difference between Confidence Intervals and Point Estimates?
Answer: As an estimate of a population parameter, point estimation offers us a specific value. Estimators for population parameters are calculated using the Method of Moments and the Maximum Likelihood estimator techniques. A confidence interval is a range of values that is most likely to include the population parameter.
The confidence interval is typically selected since it indicates the likelihood of the interval containing the population parameter. This likelihood or probability is referred to as Confidence Degree or Confidence Coefficient, and it is represented by the number 1 — alpha, where alpha is the level of significance.

Q. 22 What are some of the characteristics of the Normal Distribution?
Answer: The below are the properties of the normal distribution:
- One mode (unimodal)
- Symmetrical – the left and right halves are mirror reflections of one another.
- The maximal height (mode) at the mean is bell-shaped.
- The mean, mode, and median are all in the middle.
- Asymptotic
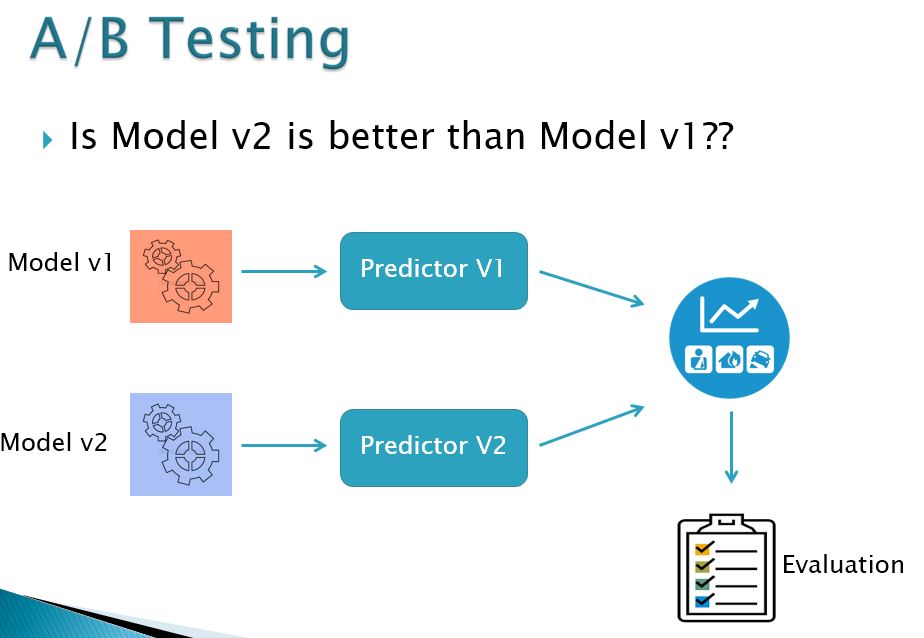
Q. 23 What exactly is the purpose of A/B testing in Data Science?
Answer: It’s a test for a randomized experiment using two variables, A and B. The aim of A/B Testing is to find any modifications to the web page that will maximize or enhance the interesting outcome. A/B testing is a great way to figure out what your company’s greatest online advertising and marketing methods are. Everything from website text to sales emails to search advertising may be tested with it. Analyzing the clickthrough rate for a giant banner is an example of this.
Q. 24 What exactly is a p-value?
Answer: A p-value can assist you to evaluate the strength of your results while doing a test in statistics. A p-value is an integer that ranges from 0 to 1. The strength of the outcomes will be determined by the value. The Null Hypothesis is the assertion that is being tested.
A low p-value (0.05) demonstrates strength against the null hypothesis, implying that the null hypothesis can be rejected. A high p-value (0.05) implies that the null hypothesis is strong, which suggests that we can accept it. A p-value of 0.05 shows that the hypothesis may go either way.
To put it differently, if you’re looking for a unique method to express yourself,
- High P values indicate that your data is most likely true null.
- Low P values indicate that your data is unlikely to be true.
Q. 25 How do you measure the statistical power of sensitivity and what does it mean?
Answer: Sensitivity is frequently used to test a classifier’s accuracy (Logistic, SVM, Random Forest etc.). “Predicted True Events/ Total Events” is the definition of sensitivity. True events are those that occurred and were predicted by the model to occur. Seasonality may be calculated with relative ease.
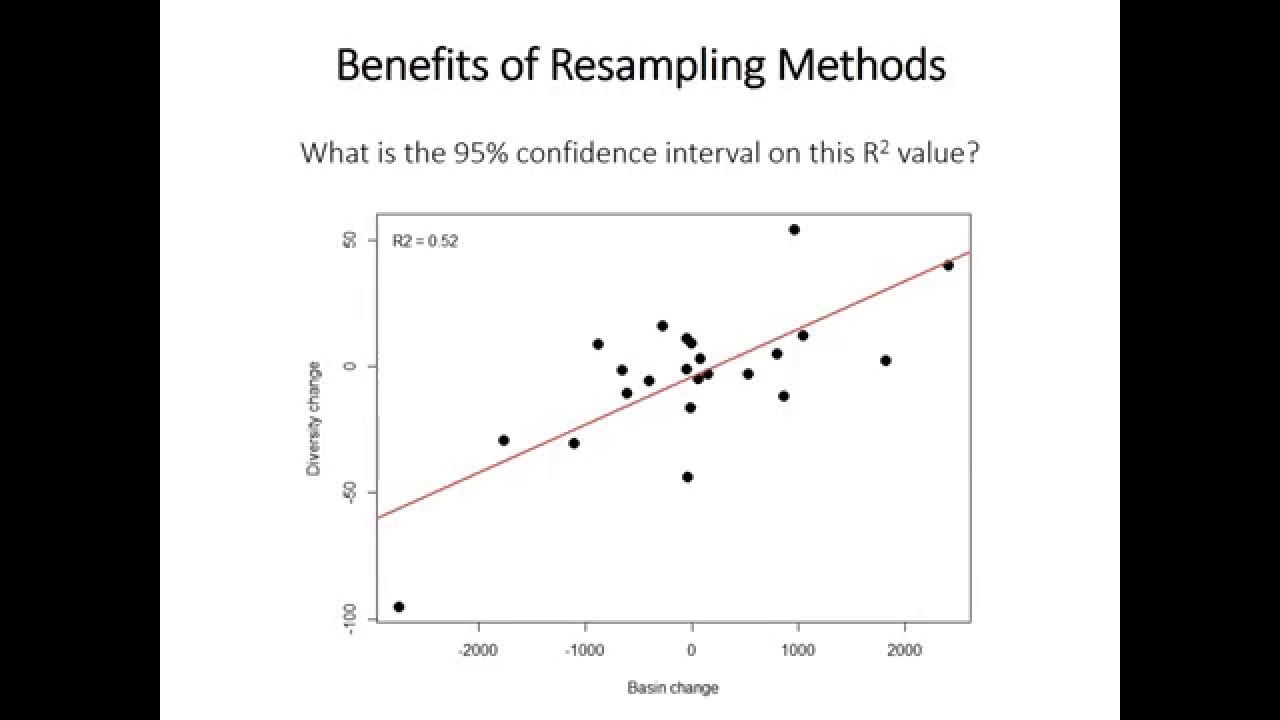
Q. 26 What is the purpose of re-sampling?
Answer: In any of the following situations, resampling is performed:
Using subsets of accessible data or selecting randomly with replacement from a collection of data points to estimate the accuracy of sample statistics When doing significance tests, substituting labels on data points. Using random subsets to validate models (bootstrapping, cross-validation).
Q.27 What is the definition of regularization? What is the benefit of it?
Answer: Regularization is the addition of tuning parameters to a model in order to promote smoothness and avoid overfitting. Adding a constant multiple to an existing weight vector is the most common way to accomplish this. The L1 (Lasso) or L2 (Lasso) constant is frequently used (ridge). The loss function generated on the regularized training set should then be minimized by the model predictions.
the model predictions.
Q.28 What is the Law of Large Numbers, and how does it apply to you?
Answer: It’s a theorem that outlines what happens when you repeat an experiment a lot of times. Frequency-style thinking is based on this theory. It claims that the data obtained, variance, and standard deviation all converge to the value they’re attempting to estimate.
Q. 29 What Are the Different Kinds of Biases That Can Happen During Sampling?
Answer: The different kinds of Biases that can happen during Sampling
Bias in selection
Due to a bias in media coverage
Survivorship bias.
Q. 30 What is Survivorship Bias, and how does it affect you?
Answer: It is the conceptual mistake of concentrating on factors that aid in the survival of a process while carelessly dismissing others that failed due to lack of prominence. In a number of ways, this might lead to incorrect conclusions.
Q. 31 What is the definition of selection bias?
Answer: When the sample obtained is not representative of the population to be studied, selection bias develops.
Q.32 What Are Confounding Variables, and How Do They Work?
Answer: In statistics, a confounder is a factor that impacts the relationship between variables. If you’re looking into whether a lack of activity causes weight gain, for example,
Lack of exercise = uncontrollable variable
The dependent variable is weight increase.
Any additional variable that influences both of these variables, such as the subject’s age, would be a confounding variable here.
Q.33 Explain the concept of Star Schema.
Answer: It’s a classic database structure with a single core table. Satellite tables translate IDs to physical names or descriptive and can be linked to the central fact table via ID fields; these tables are known as lookup tables and are most effective in real-time applications since they save a large amount of memory. To retrieve information faster, star schemas may use many levels of summaries.
Q.34 How does Cluster Sampling function and what is it used for?
Answer: Cluster sampling is a strategy used once it becomes impossible to examine the target group distributed across a broad region and simple random sampling cannot be performed. A cluster sample is a possibility sample with each sampling unit consisting of a collection of objects.

For example, a scientist in Japan wishes to assess high school pupils’ academic performance. He can split Japan’s total population into several groups (cities). The researcher then uses simple or systematic random selection to choose several clusters based on his study.
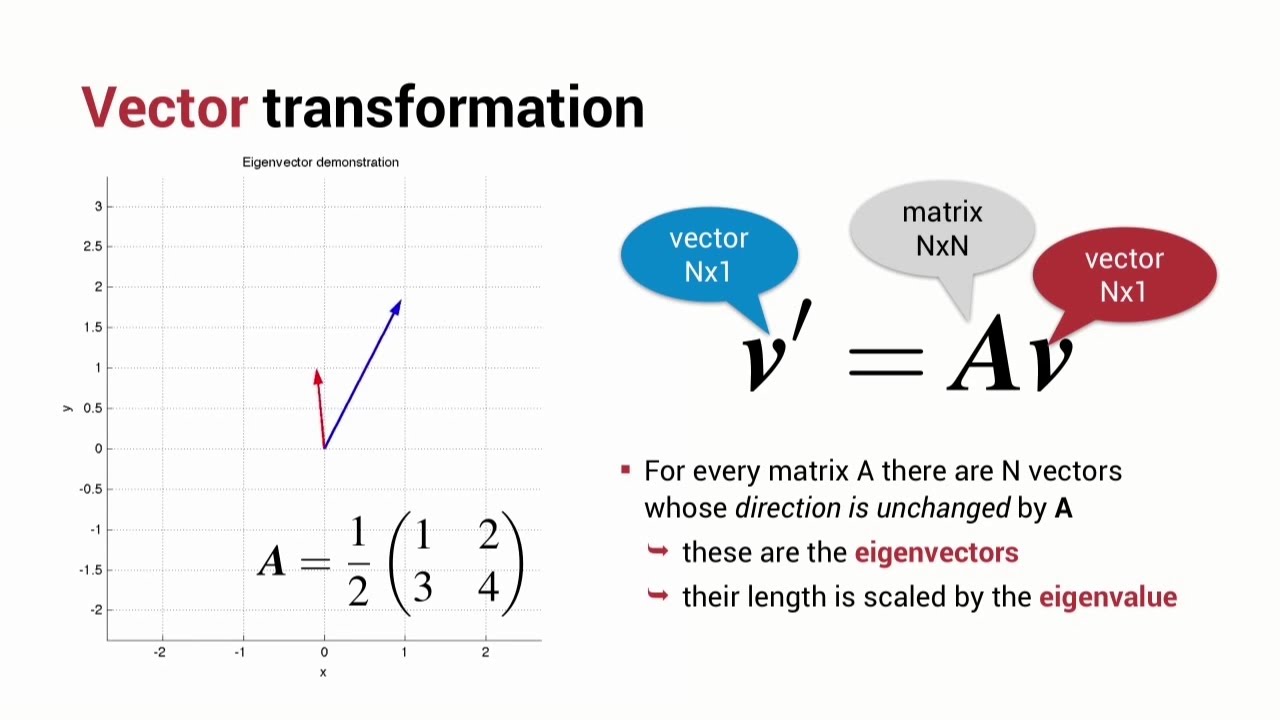
Q.35 Define the terms Eigenvectors
Answer: Understanding linear transformations require the practice of eigenvectors. In data analysis, the eigenvectors of a correlation are frequently calculated. The directions along which a linear transformation flips, compresses, or stretches are known as eigenvectors.
Q.36 Can you think of any instances in which a false positive is more significant than a false negative?
Answer: Let’s start by defining false positives and false negatives. False Positives occur when you incorrectly classify a non-event as an event, often known as a Type I mistake.
False Negatives, also known as Type II errors, occur when you incorrectly categorise occurrences as non-events.
Let’s imagine an e-commerce business decides to provide a $1000 gift certificate to consumers who are expected to spend at least $10,000 on merchandise. They send free voucher mail to 100 consumers without requiring a minimum purchase since they expect to profit at least 20% on products sold for more than $10,000. Now the question is whether we should deliver the $1,000 gift certificates to consumers who have not made any purchases but have been recorded as having made $10,000 in purchases.
Q. 37 What does the phrase Eigenvalue mean to you?
Answer: The magnitude of the transformation in the direction of the eigenvector, or the factor by which the compression occurs, is referred to as eigenvalue.
Q. 38 Cross-validation is a term that has to be explained.
Answer: Cross-validation is a model evaluation approach for determining how statistical analysis results would generalize to a different dataset. Typically employed in situations when the goal is to forecast and the user wants to assess how accurately a model will perform in practice. Cross-validation aims to define a data set to test the model in the training stage (i.e. validation data set) to avoid overfitting and provide insight into how the model will generalize to an independent data set.
Q.39 What is Machine Learning, and how does it work?
Answer: Machine Learning is the research and development of algorithms that can learn from and predicts the outcome variable. Computational statistics is closely connected to this. Predictive analytics is a term used in the business world to describe the process of developing sophisticated models and algorithms that lend themselves to prediction. The picture below represents the different fields in which Machine Learning excels.
Q. 40 What does ‘Naive’ mean in a Naive Bayes model?
Answer: The Bayes Theorem is the foundation of the Naive Bayes Algorithm. The possibility of an occurrence is described by Bayes’ theorem, which is based on previous information of variables that may be connected to the event.
The Algorithm is referred regarded as “naive” since it draws conclusions that may or may not be true.

Q.41 In SVM (support vector machine), what are the various kernels?
Answer: In SVM (support vector machine), there are four different types of kernels.
Kernel with a straight line
The polynomial kernel
Kernel with a radial basis
Kernel with a sigmoid shape.

Q. 42 In Decision Tree, what is pruning?
Answer: Pruning is a machine learning and algorithm is proposed approach for reducing the size of decision trees by eliminating parts of the tree that have insufficient capacity to categorise cases. Pruning, or the reverse of the split, is the act of removing sub-nodes from a decision node.
Q. 43 What is logistic regression and how does it work? Give an example of when you’ve recently utilized logistic regression.
Answer: The logit model, often known as logistic regression, is a strategy for predicting a binary result from a linear function of predictor variables.
For instance, suppose you want to forecast if a certain political leader would win or lose an election.
The outcome of the forecast is binary in this case, i.e. 0 or 1 (Win/Lose).
The amount of money spent on an electoral campaign by a specific candidate, the amount of time spent campaigning, and so on would be the predictor variables in this case.

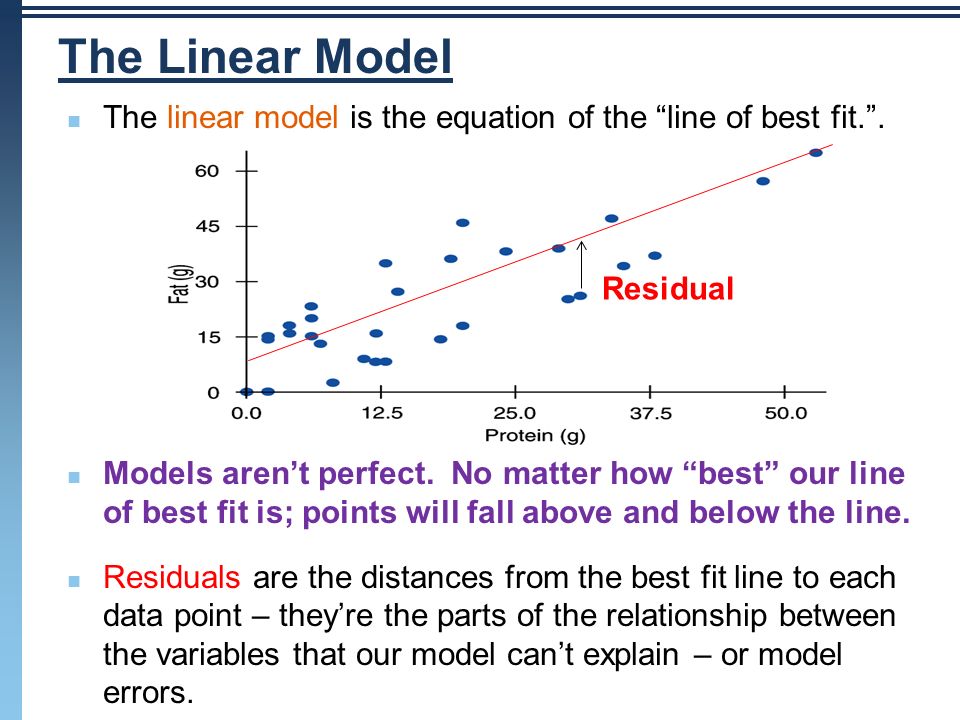
Q. 44 What is Linear Regression and whereby how does it operate?
Linear regression is a statistical approach that predicts the value of a variable Y based on the value of another variable X. The predictor variable X is referred to as the predictor variable, whereas the criteria variable Y is referred to as the criterion variable.
Q. 45 What Are the Cons of Using a Linear Model?
Answer: The linear model has a number of flaws, including:
- The mistakes are assumed to be linear.
- It isn’t suitable for the count or binary results.
- There are certain difficulties with overfitting that it can’t fix.
Q. 46 Ensemble Learning: What is it and How Does It Work?
Answer: Ensemble Learning is the process of integrating a varied group of learners (individual models) to improve the model’s stability and predictive capacity.

Q. 47 What particularly do you determine by the term “deep learning”.
Answer: Deep Learning is a machine learning paradigm that has showed tremendous promise in recent years. This is due to the fact that Deep Learning has a lot in common with how the human brain works.
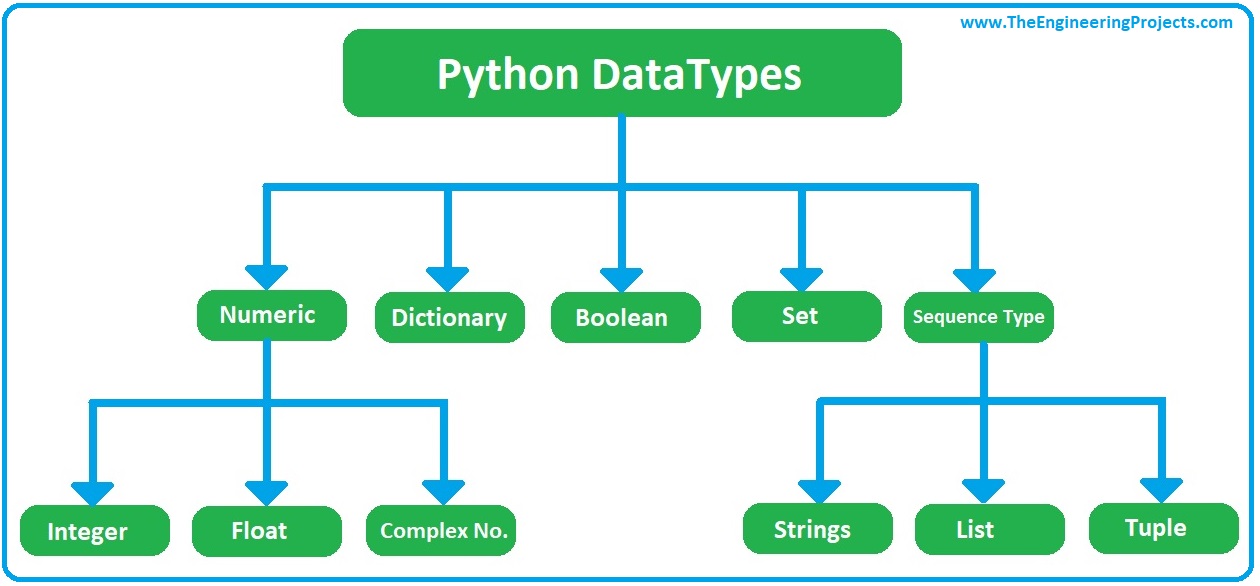
Q.48 What is Python in the field of Data Science and how does it work?
Answer: Python has evolved to become one of the world’s most popular and widely used programming languages, despite its humble origins as a hobby project named after Monty Python. Python is used for big data, machine learning, and even designing in addition to website design & development.
Q.49 What is a Boltzmann Machine, and how does it work?
Answer: Boltzmann machines use a basic learning method to find interesting characteristics in the dataset that indicate complicated regularities. The Boltzmann machine is being used to find the best weights and quantities for a particular issue. In networks with many layers of feature detectors, the learning method is extremely sluggish. The “Restricted Boltzmann Machines” algorithm is quicker than the others since it just contains one layer of feature detectors.

Q.50 What is a Computational Graph, and how does it work?
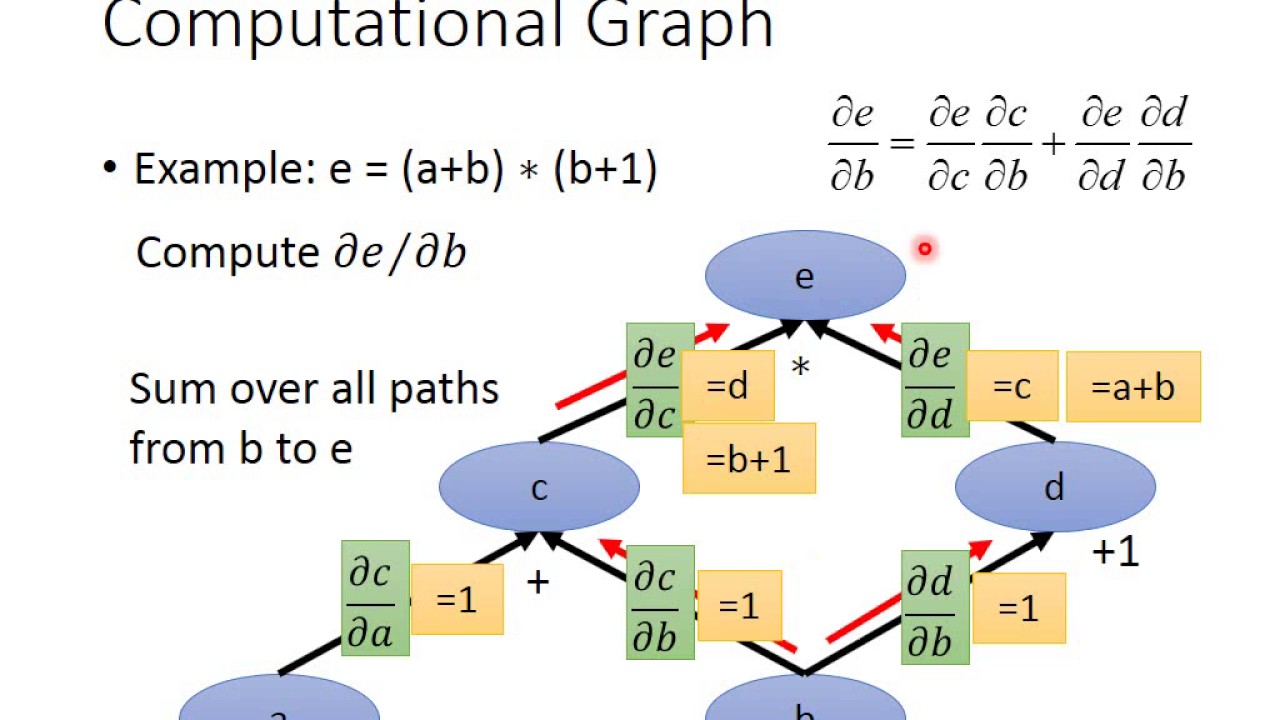
Answer: The construction of a computational graph is the basis of a TensorFlow. The edges represent tensors, whereas the nodes represent mathematical operations. Because data flows in the shape of a graph, it’s also known as a “DataFlow Graph”.
Conclusion
Endurance, statistical, and software engineering abilities are required for this procedure, as well as skills for identifying data biases and troubleshooting logs. In India, the scope of data science has a variety of uses. It is our need to find out the way that can drive us to it. Students can enrol in data science courses at institutions such as Henry Harvin Education. Several training schools provide both online and classroom training in data science courses. The data science classes taught by Henry Harvin will give you a good sense of the scope of data science and how it is progressing. Python for Data Science, Data Science for R, Data Science with Python, and other data science courses are available at Henry Harvin. The scope of Data science has a wide potential and a lot of career opportunities.
Recommended Reads:
- TOP 20 DATA SCIENCE COURSES ONLINE
- TOP 15 DATA SCIENCE COURSES IN BANGALORE
- BEST DATA SCIENCE COURSES IN INDIA WITH PLACEMENT
- TOP 18 DATA SCIENCE COURSES IN MUMBAI
- WHAT IS THE FUTURE SCOPE OF DATA SCIENCE
FAQs
In India, the scope of data science seems to have a lot of potentials. It will create jobs in India, which is no stranger to scientific and technological advancement. We’re hot in IT and healthcare, and we’ve got a big presence in a lot of other areas. These businesses rely on data science to make better decisions based on data that reveals customer preferences and helps advertise products to the proper audience. The scope of data science has immense recognition and a lot of job possibilities.
The names of the institutes that teach data science courses are listed below:
• Henry Harvin
• Jigsaw Academy
• Edvancer.
• Imarticus Learning.
• Edureka.
• Nikhil Analytic
• Ivy Professional School
• Inventateq
SVM is an abbreviation for Support Vector Machine.
DJ Patil and Jeff Hammerbacher are the fathers of data science.
The term tf-idf stands for Frequency, inverse document frequency
John Mashey, he claims, is the father of the phrase Big Data.
Big Data is defined as data that is extremely large. Big data is a word that refers to a large collection of data that continues to expand rapidly over time. Examples of Big Data analytics include financial exchanges, social media platforms, and aircraft engines, among others.








{kind=link}
Hi, I read your blog, and I like the roles and responsibilities of the data scientist part very much. For more information follow
I want to thank the writers for taking the effort and making a write up on the Data Science Interview Q/A. This is a great way to know a different perspective on this topic.
This is one of the best writings I have read in recent times. This article gives a lot of insight on the Data Science topic and it is refreshing to see a fresh take on the topic. I really appreciate uploading this article.
This is a great share. I was able to find out several new facts on the topic that I know little less about. Thank you for this share.
I was stressed out in finding the right place to do the Data science interview Question and now with the help of this blog post, I am glad I found the right place to do it.
I am so glad I found an actual article that explains and sticks with the actual topic. Really impressive and I learned a lot from Data Science Question for Interview. Great share.
Hello!
I am interested in data science course.. Can you please guide me through eligibility and procedure?
I was really lost in regards to finding the data science interview questions and answers and this blog post saved me and guided me in interview preparation.
Wonderful writing from the team. I was really glad that finally a useful blog post on the data science interview questions and answers.
I was stressed out in finding the right place to do the Data science interview Question and now with the help of this blog post, I am glad I found the right place to do it. Thank you for providing all the appropriate details. It was really helpful and worth reading. With the help of this to-the-point information on the Data Science courses, now I would be able to analyze better.
I am so glad I found an actual article that explains and sticks with the actual topic. Really impressive and I learned a lot from Data Science Question for Interview. Great share.
This is one of the best writings I have read in recent times. This article gives a lot of insight on the Data Science topic and it is refreshing to see a fresh take on the topic. I really appreciate uploading this article. Everything about this blog post is filled with all the main and important things about Data Science Training. This is a perfect piece of writing.
There are not so many articles like this one explaining the data science interview questions and answers This is a great way of learning about it. I was stressed out in finding the right place to do the Data science interview Question and now with the help of this blog post, I am glad I found the right place to do it.
This post of you is looking so informative and knowledgeable post keep on posting like this kind of blog as much as you can keep on posting like this kind of blog. I was really lost in regards to finding the data science interview questions and answers and this blog post saved me and guided me in interview preparation. I really appreciate uploading this article.
I was really lost in regards to finding the data science interview questions and answers and this blog post saved me and guided me in interview preparation. This is one of the best writings I have read in recent times. This article gives a lot of insight on the Data Science topic and it is refreshing to see a fresh take on the topic. I really appreciate uploading this article.
This is really a great course. Although, I am studying Data Exploration and Visualization for Data Science in school, there was a lot to gain from the course and a lot that I did not know. It really gave me a perspective of what is data science today and it surely helped me get a direction into the field and I am more confident now as to what I want to do in my start of the career as a Data Science and I was really lost in regards to finding the data science interview questions and answers and this blog post saved me and guided me in interview preparation.
I can easily share this write up with any learners. This is packed with necessary information. Keep up the amazing work. Wonderful writing from the team. I was really glad that finally a useful blog post on the data science interview questions and answers. I was really lost in regards to finding the data science interview questions and answers and this blog post saved me and guided me in interview preparation.